Over the course of last year, I’ve gone over to Wei’s workplace numerous times to disturb her and her colleagues during their internal sharing, not to be confused with the community meetup, React Knowledgeable. I think the internal sharing’s unofficial name is RK Originals, maybe. Who knows?
Most time, I just sit there and do nothing, other times, I talk about stuff. The last thing I talked about was the Web Speech API, which stemmed from one of the many stupid ideas I have. Basically, I wanted to yell at my browser and make it change colours on a website.
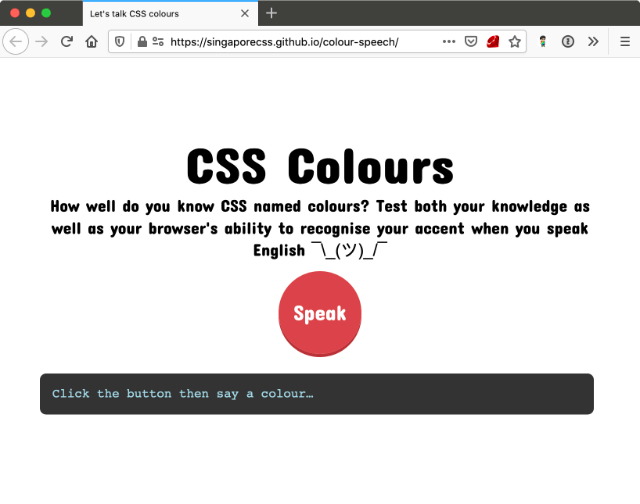
It was for the 4th anniversary of Talk.CSS.
What do you mean, why?
So anyway, stupid website was built, and the yelling worked. I had to yell because until today, I have no idea where the microphone is on my MacBook. ¯\_(ツ)_/¯
During the talk, we messed around with the different options for voices (and hence accents), but we soon found that other than English, the options for other languages were limited.
Which led me to dig a little deeper into how international the Web Speech API actually is.
What is this Web Speech API?
The Web Speech API is not a web standard, it is a community report developed and published by the Speech API Community Group, with the first draft released by in 2012.
According to the document, this API is meant to:
enable developers to use scripting to generate text-to-speech output and to use speech recognition as an input for forms, continuous dictation and control
Note the 2 distinct parts, namely text-to-speech, where your browser can read out the text on the screen, and speech recognition, which lets us use voice as an input and interface medium.
Speech recognition in the browser. Now that sounds pretty interesting. Browser APIs are essentially Javascript. Which is why someone like me who never went to school for Computer Science, can somehow cobble together projects that go beyond just a webpage.
I love the web.
But upon some further research, I soon realised that speech-to-text is not like text-to-speech. If you read through the Mozilla Wiki for the Web Speech API, it states that the speech recognition portion of the WebSpeech API allows websites to enable speech input within their experiences.
But it is not speech recognition by the browser. It is up to individual sites to determine how voice is integrated into the experience, how it is triggered and how to display recognition results.
In a sense, speech-to-text is slightly more complicated than text-to-speech because the processing is not done locally. Instead, the audio clip is sent over to Google’s Cloud Speech-to-Text.
The Speech to Text section of Google’s privacy whitepaper states that:
Chrome supports the Web Speech API, a mechanism for converting speech to text on a web page. It uses Google’s servers to perform the conversion.
Using the feature sends an audio recording to Google (audio data is not sent directly to the page itself), along with the domain of the website using the API, your default browser language and the language settings of the website.
Cookies are not sent along with these requests.
This is why support for the SpeechRecognition interface of the WebSpeech API currently looks like this:

Note: I’m using the caniuse.com embed, which as of 28 Dec 2019, shows experimental support in Chromium-powered browsers only. So if you’re reading this in the far future, I hope it’s more green than red.
Then I discovered Mozilla’s DeepSpeech, an open source Speech-To-Text engine, which implements a Tensorflow-trained model based on this research paper titled Deep Speech: Scaling up end-to-end speech recognition, published by Baidu.
In Firefox Nightly 72.0a1 (2019-10-22) and newer, the SpeechRecognition API is available behind a flag, and you have to turn the media.webspeech.recognition.enable and media.webspeech.recognition.force_enable preferences on to use it.
For now, the audio is processed by Google’s Cloud Speech-to-Text but Mozilla has plans to replace the service with DeepSpeech in 2020.
While reading the WebSpeech API document, I was curious about the language used to define the interface. It was then that I learned of the existence of the Web IDL, which is an interface description language used to describe interfaces to be implemented by browsers 🤯
Making my browser understand my yelling
People who are a lot more early-adopter than myself have been talking about voice interfaces and the WebSpeech API for years prior. So in a bid to get myself a little more familiarised, I decided to do what many web developers seem to gravitate toward.
I built a website (I don’t know what constitutes an app so ¯\_(ツ)_/¯).
Specifically, I built a website I can yell CSS at. Okay, slightly untrue. I technically am yelling colours at the website, but named colours are legitimate CSS values, so…
This didn’t require too much work because CSS values are by default in English (as with practically all programming languages). Speech-to-text quality for the English language is probably the most spot-on around, I’m guessing.
A bit about speech recognition
Speech recognition systems are meant to help computers parse and identify what is being said from human speech. If this sounds simple to you, I can assure you it is not. I mean, as a human, I can’t even parse and identify what other humans say sometimes.
So current technology is unable to listen to any speech in any context and transcribe it accurately. Current speech recognition systems limit the bounds of what they listen to by using grammars. Grammars determine what the system should listen for and describe the utterances an user might say.
The WebSpeech API uses the JSpeech Grammar Format. If you peek at this specification, it defines a grammar as a set of rules that together define what may be spoken. I’m calling mine <colour>.
const colours = ['maroon', 'darkred', 'brown', … /* All 148 named CSS colours as an array of strings */];
const grammar = '#JSGF V1.0; grammar colours; public <colour> = ' + colours.join(' | ') + ' ;';
The | character is used as a separator for the list of colours I want in my defined grammar. Given that we have 148 named CSS colours, it’d be easier to have them in an array then use join() to format the strings nicely.
Basic idea and interface
What I had in mind at the start was something along the lines of this:
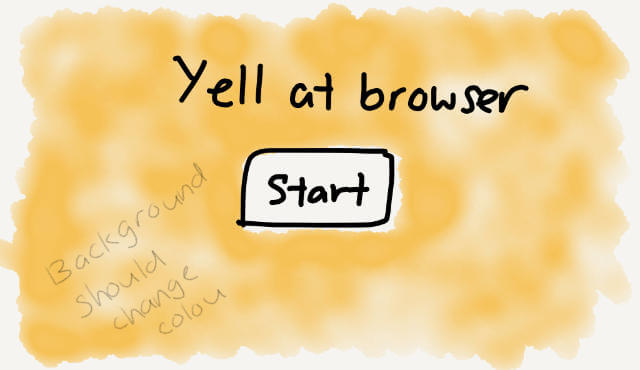
I assumed there needed to be some sort of button to trigger the permissions prompt that I often see when the browser wants to use your microphone for things. Since it’s the only thing on the page, might as well make it huge, right?
And then, once we can capture someone’s voice, we can transcribe that into a usable CSS named colour to be applied to the background of the site, preferably using CSS custom properties.
:root {
--bg-colour: transparent;
}
body {
background-color: var(--bg-colour, transparent);
}
/* namedColour should be the result from the speech recognition engine */
docBody.style.setProperty('--bg-colour', namedColour);
That’s the general idea.
Someone did it already
A little bit into the project, I found that MDN already had a tutorial plus demo of a Speech color changer. Oh well.
But I must say that it is a very in-depth and well-written tutorial so if you’re interested in getting started, I highly recommend it.
The bits of my website which use SpeechRecognition and SpeechSynthesis are similar to the demo, but I still ran into some trouble with the voiceschanged event for cross-browser compatibility.
I suppose that’s what you get with experimental technologies and implementations, code gets stale real quick. So while we are on the topic of cross-browser support, I start off the code with this bit:
const speechRecognition = window.webkitSpeechRecognition || window.mozSpeechRecognition || window.msSpeechRecognition || window.oSpeechRecognition || window.SpeechRecognition;
const speechGrammarList = window.webkitSpeechGrammarList || window.mozSpeechGrammarList || window.msSpeechGrammarList || window.oSpeechGrammarList || window.SpeechGrammarList;
const speechSynthesis = window.speechSynthesis;
That’s pretty much to cover different browser implementations if they decide to use vendor-prefixes.
if (speechRecognition !== undefined) {
addClass('speech');
detectSpeech();
} else {
addClass('no-speech');
}
Also, sprinkle on some CSS classes to indicate if a browser doesn’t support SpeechRecognition yet. I used to do this with pseudo-elements when I didn’t or couldn’t add an additional HTML element to hold the warning text, but realised that was a really inaccessible way to do things.
My suggestion for messing around with experimental APIs is to have a script to detect if the browser supports it or not, then design and build your demo or application to handle either scenario. It doesn’t have to be a major effort, sometimes a small message will do.
Less talk more code
Now, on to the meat of the project. We start off by creating a new speechRecognition() instance as well as a new speechGrammarList(), to hold all our SpeechGrammar objects.
function detectSpeech() {
const recognition = new speechRecognition();
const speechRecognitionList = new speechGrammarList();
The speechGrammarList() object has a method called addFromString(), which takes in a our grammar as a string. There is an optional second parameter that defines the weight of this grammar in relation to others in the array.
speechRecognitionList.addFromString(grammar, 1);
The speechRecognition() instance also has a number of attributes which we can set. The first thing is to add our SpeechGrammarList to the instance with the grammars attribute. Use lang to set the language of the recognition for the request.
recognition.grammars = speechRecognitionList;
recognition.lang = 'en-US';
The other 3 attributes are continuous, which allows the user agent to return more than 1 final result representing multiple consecutive responses to starting a recognition. interimResults controls whether interim results of the recognition are returned and maxAlternatives sets the maximum number of alternatives returned.
All these attributes have default values which I left alone because my application only used the most simple of basic functions.
The speechRecognition() instance also has a number of methods, which are used to actually do stuff. Calling the start() method indicates that you want the service to start listening and matching grammars with the input media stream. I trigger this when the big ol’ button is pressed.
micBtn.addEventListener('click', function() {
recognition.start();
consoleLog.innerHTML = 'Ready to receive a colour command.';
}, false);
Speech recognition on the web, like many web APIs, is an event-driven interface. SpeechRecognition uses the DOM Level 2 Event Model for this, and we can listen to a bunch of events to know when to make our application do certain things.
The most important, IMO, is when results come in. The result event will be fired when a result is successfully received. We get returned an object called the SpeechRecognitionResultsList that has a bunch of SpeechRecognitionResult objects.

recognition.onresult = function(event) {
const last = event.results.length - 1;
const colour = event.results[last][0].transcript;
const sanitiseColour = colour.replace(/\s/g, '');
consoleLog.innerHTML = 'You probably said: ' + sanitiseColour + '.\nConfidence: ' + event.results[0][0].confidence;
docBody.style.setProperty('--bg-colour', sanitiseColour);
}
To get to the transcript of what was said and sent to the recognition engine, we use event.results[last][0].transcript. We can use that syntax because the results object comes with a getter.
We then remove the spaces between words because CSS colour values don’t work with spaces, then print the result to screen. That same value can be used to update the CSS custom property of --bg-colour and change the colour of the background of the web page.
After all is said and done, we want to stop listening to more audio, so call stop() when the speechend event fires.
recognition.onspeechend = function() {
recognition.stop();
}
If the speech recognition engine can’t tell what was being said, the nomatch event will fire and we can inform the user that we didn’t pick up what was said.
recognition.onnomatch = function() {
consoleLog.innerHTML = 'Sorry, could not tell what you said.';
}
And finally, in case of some other error, we want to display that to the user as well.
recognition.onerror = function(event) {
consoleLog.innerHTML = 'Recognition error: ' + event.error;
}
I then got the hare-brained idea to add the second part of the WebSpeech API into this ridiculous demo as well. Because why shouldn’t we get the browser to read the results back to us?
Making the browser respond
I was under the impression that text-to-speech could be done locally but I also noticed one of the SpeechSynthesis methods was getVoices(), which returns a list of available voices on the current device.
So I had a function that would populate a <select> element with a list of voices to pick from the read the results. getVoices() returns an array, which we can then loop over and generate <option> values for the select dropdown.
Each option would have attributes for the name of the voice (.name) and the language of the voice (.lang) which are both retrieved from getVoices().
function populateVoiceList() {
const select = document.getElementById('pickVoice');
voices = speechSynthesis.getVoices();
voices.forEach(function(voice) {
const option = document.createElement('option');
option.textContent = voice.name + ' (' + voice.lang + ')';
if(voice.default) {
option.textContent += ' -- DEFAULT';
}
option.setAttribute('data-lang', voice.lang);
option.setAttribute('data-name', voice.name);
select.appendChild(option);
});
}
After some searching around, I found this article by Flavio Copes which highlighted a cross browser issue with Chrome’s speechSynthesis.getVoices() that needed a callback when the voices had been loaded.
He mentioned that it might be because Chrome checks Google’s servers for additional languages. So I tested this with the available browsers I had on hand, namely Chrome, Firefox and Safari, both with network connectivity and without.
With or without connectivity, Firefox and Safari return the same list of voices. Fun fact, Safari includes 2 “Daniel”s, which is the en-GB voice, one of which is premium, whatever that means.
/* Chrome's Daniel */
{
default: true,
lang: "en-GB",
localService: true,
name: "Daniel",
voiceURI: "Daniel"
}
/* Firefox's Daniel */
{
default: true,
lang: "en-GB",
localService: true,
name: "Daniel",
voiceURI: "urn:moz-tts:osx:com.apple.speech.synthesis.voice.daniel.premium"
}
/* Safari's Daniel */
{
default: true
lang: "en-GB"
localService: true
name: "Daniel"
voiceURI: "com.apple.speech.synthesis.voice.daniel.premium"
}
Without connectivity, Chrome returns the same list as Firefox, but with connectivity, it returns an additional 19 voices, bringing the option list up to 66. Those voices have localService marked false.
/* only show the voice list drop down if there are results */
docBody.style.setProperty('--display', 'block');
/* populate the select with available voices as options */
populateVoiceList();
speechSynthesis.addEventListener('voiceschanged', function() {
populateVoiceList();
});
We then need to create a new SpeechSynthesisUtterance() instance using its constructor, with the text from the speech recognition results as a parameter. If people want to change the voice used to speak the result, they can do so by selecting the available voices.
const responseForm = document.getElementById('hearResponse')
responseForm.addEventListener('submit', function(event) {
event.preventDefault();
const select = document.getElementById('pickVoice');
speechSynthesis.cancel();
const utterStuff = new SpeechSynthesisUtterance(result);
const selectedVoice = select.selectedOptions[0].getAttribute('data-name');
voices.forEach(function(voice) {
if(voice.name === selectedVoice) {
utterStuff.voice = voice;
}
})
speechSynthesis.speak(utterStuff);
}, false);
This would take into account the choice of voice to be used to speak the results, and finally the speak() method would be called with the SpeechSynthesisUtterance instance passed into it as a parameter.
What about non-English languages?
The Cloud Speech-to-Text language support page lists all the languages that it supports, so I suppose it should cover everything on that list. I may be wrong, because I did not verify this.
I guess there aren’t that many WebSpeech demos around to begin with for now, much less those in languages other than English. But in order to figure things out for myself, I had to build one. The only non-English language I’m fluent in is Chinese, so guess what language the demo is in?
The code from the CSS colour thing was pretty much reusable for the WebSpeech portion. The most important thing I got out of it was what you set as recognition.lang, i.e. the string for the lang attribute of the SpeechRecognition() instance.
It took me a bit of Googling before finding this StackOverflow answer by Timm Hayes, which had the list of language codes. If you put in a language code that isn’t supported, you will get the no-speech error message.
For Chinese, I thought it would be the generic zh or zh-hans, but nooooooo.
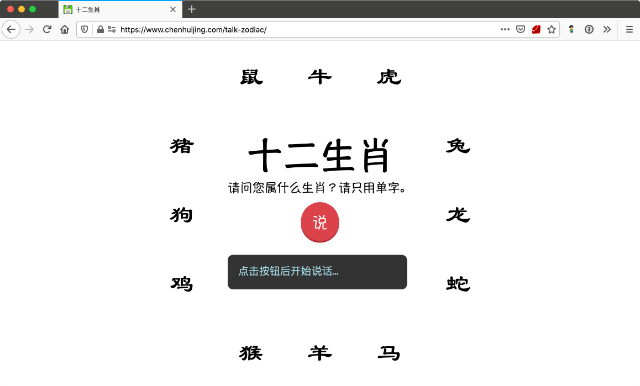
If you look at the post, you’ll find that the code for Simplified Chinese was cmn-Hans-CN, which is what I used in my test demo. Speaking of which, the test demo involves you yelling a zodiac animal name at your browser.
It’s called 十二生肖 and doesn’t take into account what happens if you don’t say the right thing. Because I haven’t gotten around to that yet. Be accurate, my friends.
You can also tweak the text-to-speech language option list by filtering for the language of choice. This is probably relevant to languages with variants only, or you could try leaving the list unfiltered for interesting results when you mix languages that are non-English.
voices.forEach(function(voice) {
const lang = voice.lang;
if (lang.includes('zh')) {
/* do the option list generation thing */
}
}
Wrapping up
This post was supposed to be published long before 2020, but here we are. Life happens, my friends. Anyway, if you speak a non-English language and build something with the WebSpeech API in it, tell me about the results, if you like.
I’m also pretty curious to see how all my demos work once Firefox switches over to Deep Speech. Exciting times for voice interfaces on the web it seems.
Resources
- Web Speech API Draft Community Group Report
- Web Speech API - Speech Recognition
- MDN: Web Speech API
- Using the Web Speech API
- MDN Web Speech API demos
- The Speech Synthesis API
- Using the Web Speech API for Multilingual Translations
- DeepSpeech 0.6: Mozilla’s Speech-to-Text Engine Gets Fast, Lean, and Ubiquitous