The third project I worked on was a website for the Redemption Hill Church. The church’s site started out as a HTML site, but as more content was added, they migrated to Wordpress a few years back. However, as the site continued to grow, it became apparent that the current structure was sub-optimal in terms of organising the various new content types the site had.
And that’s where we came in. By the time I joined the company, the design work had already been completed and the site was ready to be built. There was a spreadsheet that documented each of the various sections and how the content was to be presented. In an ideal world, the content would fit into our design perfectly, all the functionality of the site would work smoothly and all would be well across the land. Too bad unicorns don’t exist.
In retrospect, we made a number of *gasp* assumptions with regards to how the content would behave. There were a couple of issues that we ought to have pre-empted and a couple more that could have been avoided with better communication. But you live, you learn.
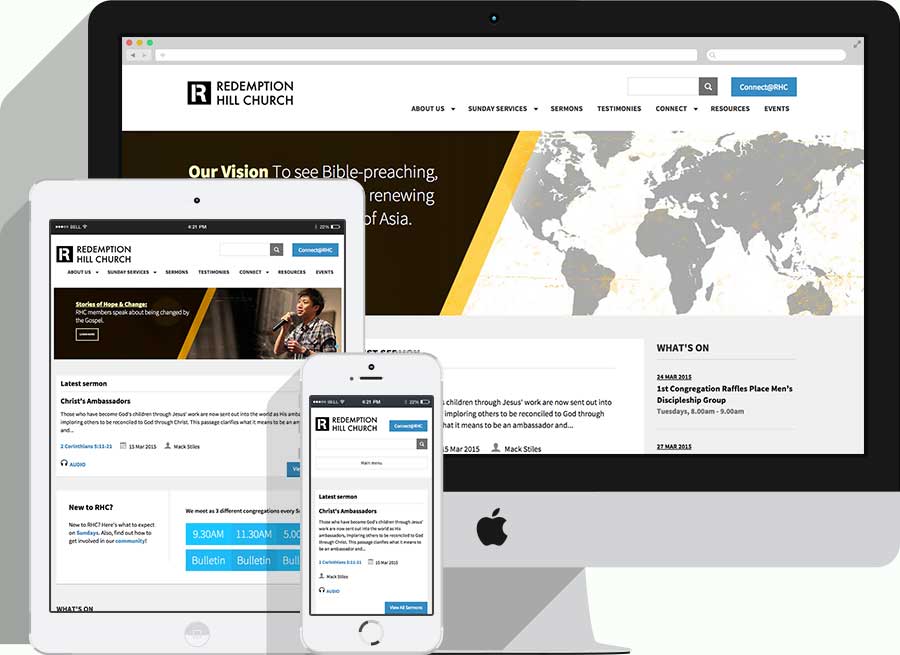
After getting my feet wet with the previous two projects, I felt more at ease with Drupal at this point. Although I’d been flying solo up till then, this time, I’d be working with another developer, Zell Liew (this is the origin story of how we became good friends). I would build the site with all its functionality, and Zell would make it look pretty. Zell is essentially the Susy guy, I mean, he did write a book about it. You really should check it out.
Given this was a migration, the site architecture was documented on a spreadsheet, so it was clear what content was coming over to the new site and what wasn’t. This spreadsheet detailed the functionality of each section of the site, down to individual pages and their URLs. Such an approach would work well if the structure of the site was already stable, and changes would only be minimal at best. However, when there are changes to entire sections of the site, keeping this document updated was quite a pain. And to be honest, we stopped updating it mid-way through the project.
Here’s where I don’t have an obvious conclusion. Could these issues of constantly changing functional requirements have been addressed by including the development team in the design process? Maybe. Would we have been unable to pre-empt these issues before actually building out the site? Perhaps. Then again, if I had more experience at the time, I could have picked up the fact that some of these design decisions didn’t make sense from an architectural standpoint. But again, many lessons were learnt because of this.
Bits about building the site
Being a church website, there were many Bible references so we thought it’d make sense to install bib.ly, which would convert all Bible references into a link that on hover, would display the Biblical text. Just in case anybody else is building a church website.
But, the trickiest part of this project was, surprise surprise (not), feeds. You can read the TL;DR version of using feeds here. An extremely important section of the site was the sermons section. The church had recordings of every almost every sermon, and accompanying study notes. With such a large number of sermons, we built a series of views exposed filters to help users find the sermons they wanted.
For the keyword search, you can actually use the filter criteria Search: search terms and it will pick up words found in any field of your content. Referenced from this post. We also used jQuery to make two of the fields conditional. For example, you can filter for a Book via a dropdown menu, and search for all sermons related to that Book. Once you select the Book, an additional Chapter field becomes available, for a more granular search, if required.
The date filter was a bit more complicated. Out-of-the-box, you can't only filter for the year without entering a month. We created two exposed filters for sermon date, and hid the month field for the first one. Once the year was selected, the second date filter would appear, but the year field was hidden and only the month field was displayed. The year selection from the first date field was passed into this second date field so the filter would work properly. As you can see, the site uses Dropkick to style select lists.
var $monthAndYear = $('.views-widget-filter-field_date_value');
$monthAndYear.hide();
$('.views-widget-filter-field_date_value_2, .views-widget-filter-field_date_value_1').find('select').dropkick({
change: function(value, label) {
if (value !== '') {
yearValue = value;
$monthAndYear.show();
$monthAndYear.find('.date-year').addClass('element-invisible');
$monthAndYear.find('select').dropkick({
change: function(value, label) {
console.log(value);
if (value !== '') {
$monthAndYear.find('.date-year').val(yearValue);
} else {
$monthAndYear.find('.date-year').val('');
}
}
});
} else {
$monthAndYear.hide();
}
}
});The data for these sermons were on the old Wordpress site. In a single body field. So I copied this list from the browser into an Excel spreadsheet and applied my Excel-fu to the data. Did I mention I love Excel? Not spreadsheets, but the program Excel. Oh, never mind.
The data actually ported quite neatly into the spreadsheet.
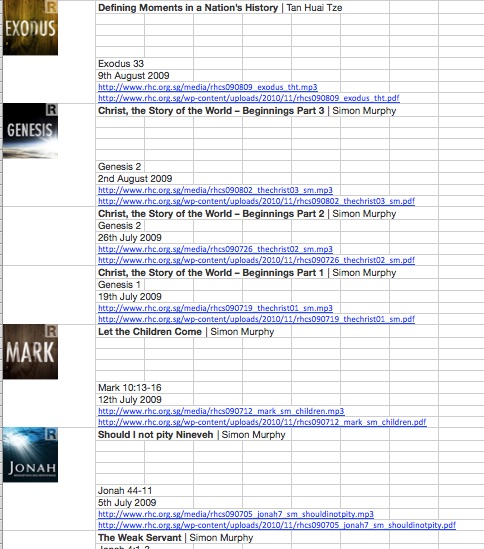
I needed to massage this into a CSV file that the feeds importer would recognise hence generate all my sermons CORRECTLY. Fun fact, when I started testing my importer, my NID count was in the low teens, something like 14. When I finally got the importer to work correctly, I was in the four thousands. Oh, all those deleted nodes.
Getting dirty with data cleansing (see what I did there)
-
Convert hyperlinks to text
I needed the URLs from the hyperlinks, not the text, which the direct copy and paste gave me. With reference to Twig's Tech Tips, create and run the following macro:
Dim Cell As Range For Each Cell In Intersect(Selection, ActiveSheet.UsedRange) If Cell.Hyperlinks.Count > 0 Then Cell.Value = Cell.Hyperlinks.Item(1).Address End If Next - Transpose each set of rows into their respective columns
=INDEX($B$1:$B$1530,ROWS(G$1:G1)*5-5+COLUMNS($G1:G1))I used the INDEX() function for this, referencing from Excel Forum. Please excuse the highlighting, turns out there’s no highlighter for Excel.
-
Adjust data as necessary
The data wasn’t as clean as I expected and there were a handful of sermons that had more or less than five rows. Because it was a manageable number, I did this adjustment manually to get all the data into the correct columns.
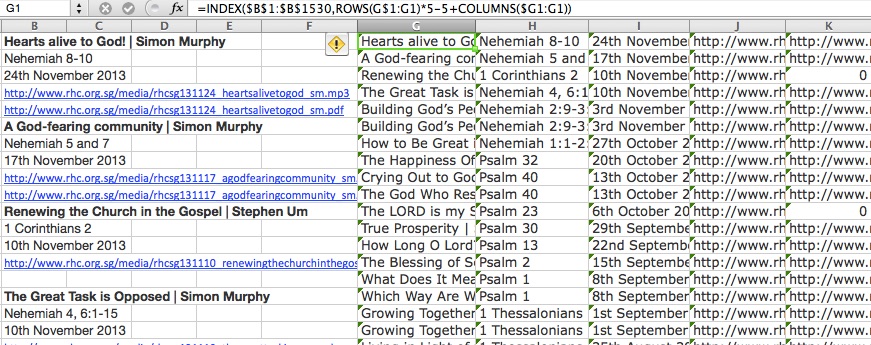
- The first column ended up with 2 different fields, thankfully with a delimiter (or separator, if that’s what you want to call it). The Text to Columns function comes in very handy here. It can be found under Data in the toolbar, and provides a wizard to guide you through the process.
-
Depending on your use-case, you may or may not need to remove line breaks from your data. Insert a blank column next to the cells that need cleaning, use this formula and drag down the column as required:
=SUBSTITUTE(A1,CHAR(13)," ") - If you’re dealing with dates and times, or anything that Excel may apply it’s own formatting to, you may need to adjust them accordingly to fit the feed importer settings or vice versa. It’s good to check the CSV file in a text editor just to make sure.
- Find and replace (⌘+F or Ctrl+F) will be a function you constantly use to tweak your data set en masse.
Although this project dragged out a little longer than we planned, it brought to light numerous flaws in our processes and made us really think about how to improve them. As the saying goes, there’s no substitute for experience. We just have to admit our shortcomings so we can work toward bettering ourselves for future projects to come.